360创始人周鸿祎在近日接受媒体采访时表示,中美在AI上的差距主要在于“确定技术方向”上,中国的优势是学习能力很快,一旦方向确定,中国将有足够的能力和机会来实现弯道超车。
很显然,这个朴实的道理也同样适用于中美竞争的其它领域,比如早些年中美竞争异常激烈的超算领域。本文我们以超算中的细分领域霸主——安腾(Anton)计算机所选择的技术路线为启发,来分析中国在超算领域弯道超车的方向选择问题。
我们通常所说的超算指的是超级计算机,是一种相较于大型计算机而言运算速度更高、存储容量更大、功能更为完善的计算机,其运算速度通常在每秒5000万次以上,并可存储容量超过百万个字节。超级计算机广泛应用于药物研发、新材料研发、飞行器设计、汽车工程、天气预报等需要用到极大运算量的科学计算领域,目前俨然是左右国与国尖端科研领域竞争结果的基础设施级别的重要科研工具。
一直以来,各国都在追求制造运算处理能力更快的超级计算机。自1942年美国发明超级计算机以来,中国、日本、英国开始跟随和进行技术攻坚,都希望自己的超算能在世界拥有一席之地。2014-2017年期间,中国的“天河二号”和“神威·太湖之光”曾连续4年占据全球超级计算机Top500的榜首,但随后又被日本和美国相继超越。

超级计算机Frontier 图片来源:维基百科
借由Top500榜单的变化趋势可以看到,从2016年到2022年的短短六年时间,最强超算的性能增长了10倍有余,这背后隐藏的是尖端半导体行业白热化的技术竞争。但是,一味地关注聚光灯下的榜单排名,反而可能会让我们忽视隐藏在水面之下可能更为重要的“战场”。
在全球超算Top500的榜单之外,还有一类采取了截然不同底层技术架构路线、专门用来解决特定领域问题的专用超级计算机,相比于Frontier、神威·太湖之光这样的通用超算来说,这些专用超算并不一味地追求运算的速度是每秒十亿亿次还是百亿亿次,而关注特定领域问题被计算解决的效率。
在这一类专用超级计算机中,最有名的就是美国D. E. Shaw研究所推出的安腾(Anton)超级计算机,安腾计算机专门被用于分子动力学模拟算法的加速,这是一种对于生命科学研究和生物制药研发领域至关重要的算法。在计算分子动力学模拟问题时,安腾计算机的计算效率比全球最强的超算Frontier还要高上近50倍。

安腾超级计算机 图片来源:网络
拥有每秒百亿亿次计算性能的Frontier毫无疑问已经是超算界的天花板了,但为何安腾计算机还能在它的基础上再优化数十倍的性能效率呢?其背后的原因就是技术路线选择的差异,使得安腾这样的专用超算在擅长的计算领域可以发挥出碾压Frontier这样顶级通用超算的能力。
顾名思义,专用超级计算机是一种针对解决特定问题而专门开发的计算机。由于CPU、GPU等通用的算力芯片无法满足特定问题对算力性能的要求,专用超级计算机通常使用ASIC芯片(Application Specific Integrated Circuit,专用集成电路),牺牲了灵活性、换来了解决特定问题的极致性能。
简单来说,ASIC芯片是一种针对特定用途定制化的高效计算芯片。这样的定制专用芯片,可靠性、保密性、算力、能效,都会比通用芯片(CPU、GPU)更强。这是因为基于芯片所面向的专项任务,芯片的计算能力和计算效率都是严格匹配于任务算法的;芯片的核心数量,逻辑计算单元和控制单元比例,以及缓存等,整个芯片架构,也是精确定制的。但也正是由于ASIC芯片针对特定需求定向开发,所以设计和制造均需要大量资金,和较长时间周期,且一旦定制,无法再次进行写操作,灵活性较差。
前文提及的安腾计算机就是这样一台采用了ASIC芯片架构的专用超级计算机。在硬件上,安腾计算机的芯片、主板、布线都由D. E. Shaw研究所特殊设计。通过特殊设计的ASIC芯片,尽可能减少数据的传输和运算,在芯片上分区域、分精度计算不同任务,突破制约分子动力学模拟速度的瓶颈——原子间相互作用力的计算。
据公开资料显示,“整个安腾计算机的芯片ASIC包括288个核心瓦片和24个边缘瓦片。总的来说,它提供了5.6Tbps的片外带宽。较大的Serdes物理PHYs在芯片的两个边缘都与这些瓦片相连。瓦片直接相邻,减少了未使用的芯片面积,简化了物理设计。同时,该芯片使用全局时钟网,以最小的偏移实现高时钟速度;网状结构节省了功耗,网络只占芯片TDP的5%。为了提高良率,D. E. Shaw研究所设计了安腾计算机第三代的列级冗余。如果一列有一个坏的瓦片,只要该瓦片的路由器仍在工作,该芯片就仍然可行。因此,它使用288个核心瓦片中的264个来实例化528个几何核心和528个PPIM,以及66MB的片上存储器。”
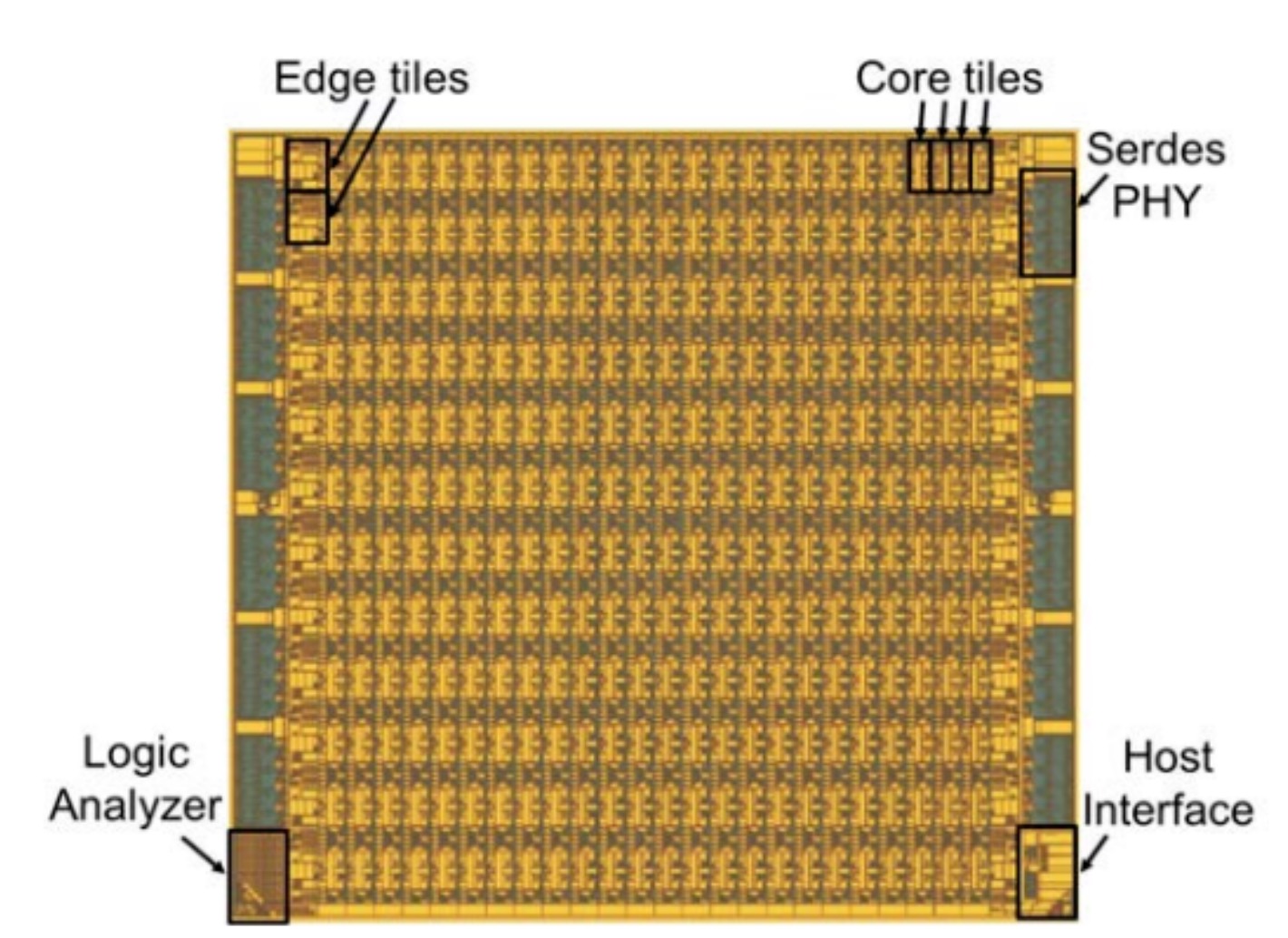
第三代安腾计算机的晶片管芯布局 图片来源: D.E.Shaw研究所
安腾计算机的出现为超级计算机硬件的进一步专业化提供了令人信服的理由。没有任何商业芯片能接近其存储密度和计算速度。目前,安腾计算机的单台机器仅采用512个节点,居然比装载了几万个CPU和GPU节点的通用超算中心快上100-1000倍!
而安腾计算机带来的超乎想象的性能提升,也让美国的制药公司和生命科学研究人员享受了长达十余年的科研技术红利。美国的科学家利用安腾计算机率先突破了困扰行业数十年的分子动力学模拟计算效率问题。自上个世纪七八十年代以来,分子动力学模拟就始终受限于严重的计算效率瓶颈,导致无法产业化应用。比如人体内典型的大分子蛋白质往往由几十万到上百万个原子构成,假设我们用分子动力学模拟方法计算一个100万原子的蛋白质运动0.001秒的“影片”,哪怕用上1000颗主流CPU并行计算,都需要耗费超过100年的时间,但如果使用安腾计算机,只需要10天就可以算完。美国制药公司Relay使用安腾计算机第二代(Anton2)对药物靶点和成药小分子的结构进行分子动力学模拟和筛选设计,用实验+计算相结合的近乎降维打击的研发方法,仅在18个月内、不到 1 亿美金就确认RLY-4008等药物的结构,一举实现了震惊医药行业的“壮举”。因为在过去的认知里,一款新药的研发最少也需要用至少10年、10亿美金才够!
随着美国持续收紧对我国的芯片禁令、不断单方面对我国升级霸权行为,我们在超算领域的发展和赶超之路无疑将会充满荆棘和泥泞。不过,在过去每一次的技术革命浪潮中,尽管我们与美国相比缺乏先发的优势,我们也一次次通过“先跟随再力争超越”的竞争策略实现弯道超车,无论是不久前的新能源汽车领域、还是当下正在发生的人工智能领域都是如此,想必在超算领域也必将不会例外。当然,我们也需要足够清醒的判断力,找到弯道超车发力的正确方向,美国安腾计算机独树一帜的技术路线和取得的巨大成功,对于我们来说无疑是一个需要纳入考量的重要方向指引。
(如有版权问题,请联系删除)
