GPU是大模型牌桌上唯一的砝码吗?——或许全世界都或多或少想摆脱英伟达这个过于强势的硬件供应商。
然而,对于被“卡脖子”的我们来说,这个问题则更加的现实和严峻。美方对我国AI发展的限制是可谓是全方位的。用中国科学院计算技术研究所研究员张云泉的话说,这包括“禁止销售高端GPU,终止大模型源代码分享以及中断生态合作。”这使得硅谷“暴力美学”式的Scale Law我们很难跟进。
在近日召开的2024中国算力发展专家研讨会上,专家们指出了一条新的路:超算。“当大模型需要1万至10万个GPU时,通过开发专用超级计算机克服高能耗、可靠性问题和并行处理限制是至关重要的”张云泉说。
超智融合:英伟达验证过的算力路
很多专家看好超级计算和智能计算的整合。这将有希望同时满足多种不同算力的应用需求。
英伟达新推出的最强芯片GB200就是这个思路,该芯片由两个B200 Blackwell GPU和一个基于Arm的Grace CPU组成。通过NVIDIA先进的 NVLink-C2C互连技术,CPU和GPU之间可以紧密协同,以减少数据在两者之间的传输时间,提高处理速度。

院士钱德沛不主张“跟着美国走”。堆芯片在短期上难以实现,从长远来看,也未必能解决真问题。“一味地增加芯片,依靠增加系统的复杂度来解决大模型的存储问题是不完全可取的”。
从美国目前的实践来看,即使卡不是问题,也已经面临了有算力没电力的尴尬。此前,马斯克的合作方甲骨文公司,就曾因提出 xAI 选建算力中心的地方供电不足,最终导致潜在的百亿合作破裂。
在最近2024比特币大会上,特朗普承诺若胜选则将通过兴建核电的方式,解决AI发展的后顾之忧。然而,模型始终在扩展,从文字到多模态,AI吞下的能耗越来越大。这种解决方式可能无疑于抱薪救火。
专家陈润生说,未来智能计算还是应该参考“人类智能”,也就是模拟人脑的运行机制。人脑的体积非常小,能耗只有几十瓦,但它所产生的智能,超过了现在最先进的、能耗相当于一整座城市的AI。
值得一提的是,我们在这个路线上已经取得了一些进展。例如天津大学医学院神经工程团队所研究的片上脑-机接口这一技术。作为尚处于起步阶段的新型混合智能体构建技术,片上脑涉及智能基础、智能通讯、智能迁移、智能融合等多个关键环节。其中智能基础作为智能体的中央处理器 CPU,是实现片上脑智能的核心,旨在能高效地模拟大脑、解析大脑。
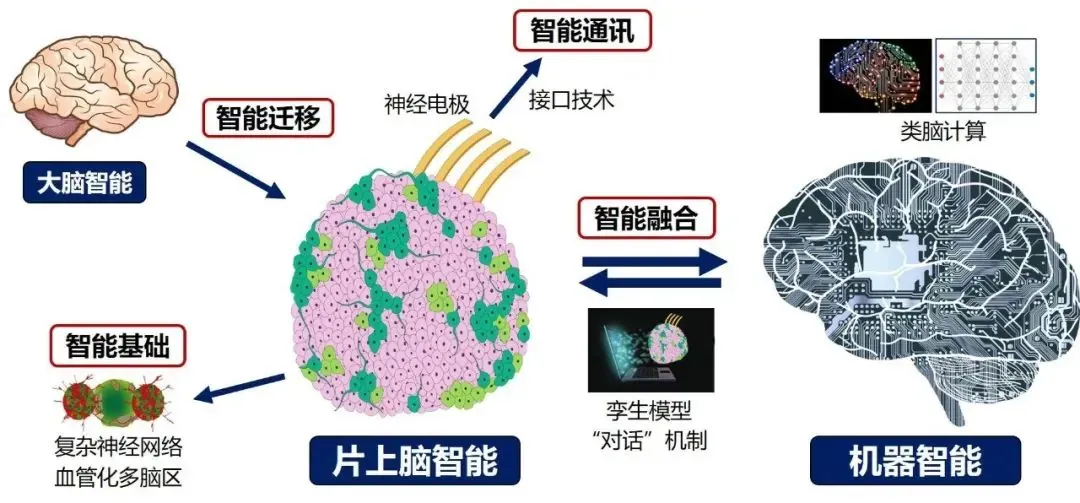
“主权级大模型”:咬紧全球领先,不掉队
7月25日,奥特曼在《华盛顿邮报》发布了一篇长文《谁将控制AI的未来》。他在长文中无不煽动地说,谁掌控AI创新和持续发展,谁就能统治未来。这篇长文的目的显而易见——鼓励社会各方,尤其是美国政府继续加大对AI的投资力度。
这在全世界都是具备参考性的。当AI成为我们这个时代的基础能力,国家级超级大模型必须要获得政策的支持和倾斜才能做成。
(如有版权问题,请联系删除)
“卡脖子”有解了?中国超算能否成为“全村的希望”?专家:不必学马斯克猛堆10万块GPU,大模型专用超算或将「破壁」算力瓶颈
