为了训出最强Grok 3,xAI耗时19天,打造了由10万块H100组成的世界最大超算集群。而在训练FSD、擎天柱机器人方面,马斯克同样不惜重金,投入了大量的计算资源。
超算Dojo,是特斯拉AI的基石,专为训练FSD神经网络而打造。
就在今天,他在德州超级工厂(Cortex)参观了特斯拉的超级计算机集群。马斯克称,「这将是一个拥有约10万个H100/H200 GPU,并配备大规模存储的系统,用于全自动驾驶(FSD)和Optimus机器人的视频训练」。
不仅如此,除了英伟达GPU,这个超算集群中还配备了特斯拉HW4、AI5、Dojo系统。它们将由一个高达500兆瓦的大型系统提供电力和冷却。
2021年特斯拉AI Day上,马斯克首次对外宣布Dojo。如今三年过去了,Dojo建得怎样了?
8000块H100等价算力,加倍下注
半个月前,网友称2024年年底,特斯拉拥有AI训练算力,等价于9万块H100的性能。
马斯克对此做了一些补充:我们在AI训练系统中不仅使用英伟达的GPU,还使用自己的AI计算机——Tesla HW4 AI(更名为AI4),比例大约为1:2。这意味着相当于有大约9万个H100,加上大约4万个AI4计算机。

他还提到,到今年年底,Dojo 1将拥有大约8000个相当于H100算力。这个规模不算庞大,但也不算小。

Dojo D1超算集群
其实在去年6月,马斯克曾透露Dojo已经在线并运行了几个月的有用任务。这已经暗示着,Dojo已经投入到一些任务的训练中。
最近,在特斯拉财报会议上,马斯克表示特斯拉准备在10月推出自动驾驶出租车,AI团队将「加倍投入」Dojo。预计Dojo的总计算能力,将在2024年10月达到100 exaflops。假设一个D1芯片可以实现362 teraflops,要达到100 exaflops,特斯拉将需要超过27.6万个D1芯片,或者超过32万英伟达A100 GPU。
500亿晶体管,D1已投产
2021年特斯拉AI Day上,D1芯片初次亮相,拥有500亿晶体管,只有巴掌大小。它具备了强大和高效的性能,能够快速处理各种复杂的任务。今年5月,D1芯片开始投产,采用台积电7nm工艺节点。
Autopilot前硬件高级总监Ganesh Venkataramanan曾表示:D1可以同时进行计算和数据传输,采用定制ISA指令集架构,并针对机器学习工作负载进行了充分优化。这是一台纯粹的机器学习的芯片。
尽管如此,D1仍没有英伟达A100强大,后者同样采用了台积电7nm工艺制造。D1在645平方毫米的芯片上放置了500亿个晶体管,而A100包含540亿个晶体管,芯片尺寸为826平方毫米,性能领先于D1。
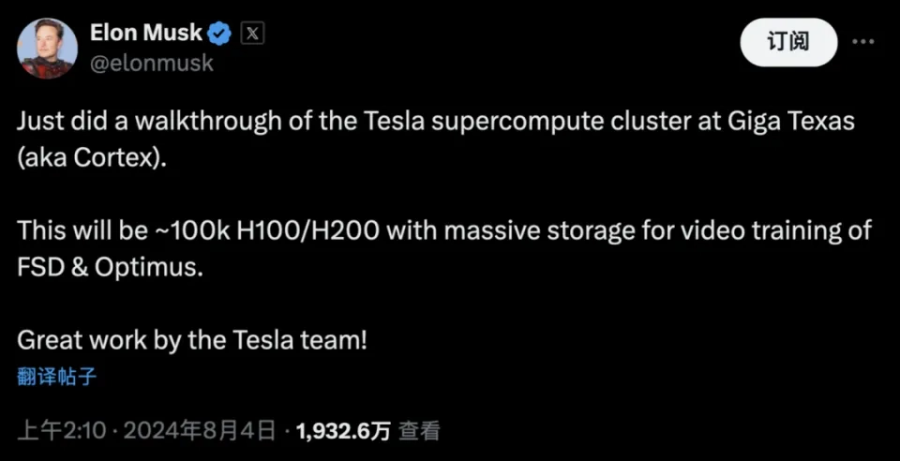
为了获得更高的带宽和算力,特斯拉AI团队将25个D1芯片融合到一个tile中,将其作为一个统一的计算机系统运作。每个tile拥有9 petaflops的算力,以及每秒36 TB的带宽,并包含电力源、冷却和数据传输硬件。我们可以将单个tile视为,由25台小型计算机组成的一台自给自足的计算机。
通过使用晶圆级互连技术InFO_SoW(Integrated Fan-Out,System-on-Wafer),在同一块晶圆上的25块D1芯片可以实现高性能连接,像单个处理器一样工作。6个这样的tile构成一个机架(rack),两个机架构成一个机柜(cabinet)。十个机柜构成一个ExaPOD。在2022年AI Day中,特斯拉表示,Dojo将通过部署多个ExaPOD进行扩展。所有这些加在一起构成了超级计算机。

晶圆级处理器(wafer-scale processor),比如特斯拉的Dojo和Cerebras的晶圆级引擎WSE,比多处理器(multi-processor)的性能效率要高得多。前者的主要优点包括内核之间的高带宽和低延迟通信、较低的电网阻抗以及更高的能源效率。目前,只有特斯拉和Cerebras拥有晶圆上系统设计。
然而,将25个芯片放在一起对电压挑战和冷却系统也是不小的挑战。
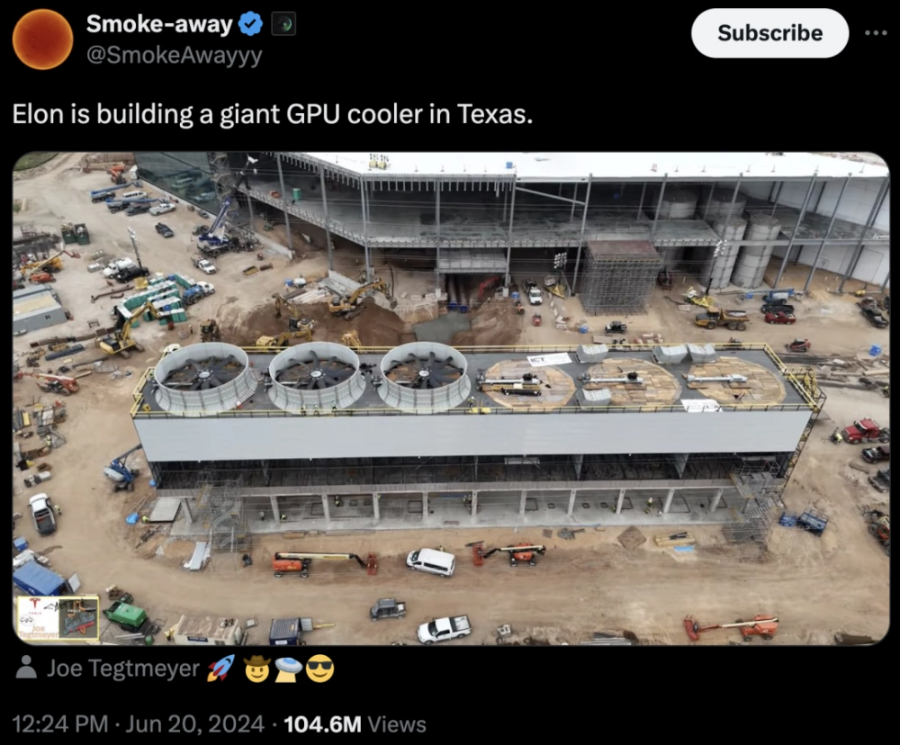
网友拍到特斯拉在德州建设巨型冷却系统
晶圆级芯片的固有挑战还在于,必须使用片上内存(on-chip memory),这不够灵活,可能无法满足所有类型的应用。Tom's Hardware预测, 下一代使用的技术可能是CoW_SoW(Chip-on-Wafer),在tile上进行3D堆叠并集成HBM4内存。
此外,特斯拉还在研发下一代D2芯片,为了破解信息流难题。与连接单个芯片不同,D2将整个Dojo tile放在了单个硅晶圆上。到2027年,台积电预计将提供更复杂的晶圆级系统,计算能力预计将提升超过40倍。
为什么需要Dojo
自动驾驶耗算力
在我们的印象中,特斯拉的主业仅限于生产电动汽车,再附带一些太阳能电池板和储能系统的业务。
但马斯克对特斯拉的期望远远不止于此。大多数自动驾驶系统,比如谷歌母公司Alphabet旗下的Waymo,仍旧依靠传统的感知器作为输入,比如雷达、激光雷达和摄像头等。但特斯拉采取的是「全视觉」路径,他们仅依靠摄像头捕捉视觉数据,辅以高清地图进行定位,再使用神经网络处理数据以进行自动驾驶的快速决策。
直观来看,显然前者是一种更简单快捷的路径,事实也的确如此。Waymo已经实现了L4级自动驾驶的商业化,即SAE所定义的,在一定条件下下无需人工干预即可自行驾驶的系统。但特斯拉的FSD(Full Self-Driving)神经网络仍无法脱离人类操作。
Andrej Karpathy曾在特斯拉担任AI负责人,他表示,实现FSD基本是在「从头开始构建一种人造动物」。我们可以将其理解为人类视觉皮层和大脑功能的数字复制。FSD不仅需要连续收集和处理视觉数据,识别、分类车辆周围的物体,还需要有与人类相当的决策速度。由此可见,马斯克想要的绝不只是能盈利的自动驾驶系统而已。他的目标,是打造一种新智能。
但幸运的是,他几乎不太需要担心数据不够的问题。目前大约有180万人为FSD支付了8000美元的订阅费(之前可达1.5万美元),这意味着特斯拉能收集到数百万英里的驾驶视频用于训练。而算力方面,Dojo超算就是FSD的训练场。它的中文名字可以翻译为「道场」,是对武术练习空间的致敬。
英伟达不给力
英伟达GPU有多抢手?看看各大科技巨头的CEO有多想跟老黄套近乎就知道了。即便财大气粗如马斯克,也会在7月的财报电话会上承认,自己对特斯拉可能没法用上足够的英伟达GPU感到「非常担忧」。马斯克说:我们看到的是,对英伟达硬件的需求如此之高,以至于通常很难获得GPU。
目前,特斯拉似乎依旧使用英伟达的硬件为Dojo提供算力,但马斯克似乎不想把鸡蛋都放在一个篮子里。尤其是考虑到,英伟达芯片的溢价如此之高,而且性能还不能让马斯克完全满意。
在硬件与软件协同这方面,特斯拉与苹果的观点类似,即应该实现两者的高度协同,尤其是FSD这种高度专门化的系统,更应该摆脱高度标准化的GPU,使用定制硬件。这个愿景的核心,是特斯拉专有的D1芯片,于2021年发布,今年5月开始由台积电量产。此外,特斯拉还在研发下一代D2芯片,希望将整个Dojo块放在单个硅片上,解决信息流瓶颈。

在第二季度财报中,马斯克指出,他看到了「通过Dojo与英伟达竞争的另一条途径」。
Dojo能成功吗
即便自信如马斯克,在谈到Dojo时,也会支支吾吾地表示,特斯拉可能不会成功。
从长远来看,开发自己的超算硬件可以为AI部门开拓新的商业模式。马斯克曾表示,Dojo的第一个版本将为特斯拉的视觉数据标注和训练量身定制,这对FSD和训练特斯拉的人形机器人Optimus来说非常有用。而未来版本将更适合通用的AI训练,但这不可避免地要踏入英伟达的护城河——软件。
几乎所有的AI软件都是为了与英伟达GPU配合使用,使用Dojo就意味着要重写整个AI生态系统,包括CUDA和PyTorch。这意味着,Dojo几乎只有一条出路——出租算力,建立类似于AWS和Azure一样的云计算平台。摩根士丹利在去年9月的报告中预测,Dojo可以通过robotaxi和软件服务等形式释放新的收入来源,为特斯拉的市值增加5000亿美元。
简言之,从目前马斯克对硬件的谨慎配比来看,Dojo并非「孤注一掷」而更像是一种双重保险。但一旦成功,也可以释放巨大红利。
(如有版权问题,请联系删除)
