
展望下一代AI算力,是讲堂新书《对话时代》的上海场研讨讲座,第二天为北京场

李根国现场演讲,分析和展望下一代算力 李念拍摄
AI热点对算力的需求
自从ChatGPT问世后,人工智能界的热点话题已经成为全社会的关注。我们先来看看最近的AI界三大热点,从个案来了解算力的需求侧。
*热点一:物理诺奖给神经网络研究者,全社会对AI高度认可

霍普菲尔德(Hopfield)和辛顿(Hinton)获诺贝尔物理奖
霍普菲尔德和辛顿所做的贡献跨越了科学和计算机界,特别是辛顿,此前已获得“图灵奖”,此次因人工智能领域的贡献而获诺贝尔奖,是各行各业对其成就的高度认可,同时也表明,人工智能就是人类未来各个领域发展的一个方向。
众所周知,人类与其他动物的区别是,人类会制造工具、利用工具。计算机刚被发明时就认为是人类大脑的延伸,是人类智力的体现。

2015年,“阿尔法狗”战胜柯洁,标志着大规模算力才能发展人工智能 图源《新民周刊》
人工智能自1950年代发展起来就特别热门,提出了用神经网络的方法来研究。后来发现算力太差无法开展,当时计算机速度只有每秒几千次、上万次。1980年代提出了神经网络新算法,但算力仍然不够。直至2015年谷歌开发出会下围棋的“阿尔法狗”(AlphaGo),才标志着新一轮的人工智能的发展。从这个方面来看,计算速度对人工智能的发展是最重要的决定性因素。只有大规模的算力才能发展人工智能,比如目前最新的GPT-4o1,之后的发展都需要大规模的算力支持。
*热点二:蛋白质结构预测表明科学范式变化,AI广泛渗透

诺贝尔化学奖垂青阿尔法折叠发明者
传统研究方式是物理实验结合超级计算。国内两位海归科学家施一公和颜宁就是运用物理实验方法研究蛋白质结构,利用冷冻电镜观察蛋白质结构,并在美国和中国都发表了许多高质量的文章,成果显著,很快就评上了院士。谷歌公司最新发布的AlphaFold是用AI做蛋白质结构预测的。
这些科学家都在做同一件事,但能看出一些明显区别,用人工智能的AlphaFold会做得很快,一次性就能预测出几十种蛋白质的结构,这叫概率计算——大致是这样的情况,但不能准确得出结果。真正的科学计算基于超级计算机,能预测出蛋白质结构,但这需要精确计算。这是两种不同的方法。人工智能计算和超算的区别就在于,一个是概率计算,另一个是精确计算。当然,最终的科学研究还是要落实到实验,真正物理上能够实现,才能确认有蛋白质结构。例如医药研究方面,许多病理的研究都基于蛋白质结构的研究。
因此,今年的诺贝尔化学奖授予蛋白质结构的发现,标志着整个科学界的认可,也意味着当前科学研究的范式发生了变化。之前的科学研究基于大量的实验观察,后来是实验观察与计算相结合,现在是以大数据和人工智能相结合的科学研究,这是一个非常重要的研究方法进化。
诺贝尔奖的颁发,更多的是唤醒人们对AI超预期发展和广泛渗透性的重视,增加人们对AI推动人类社会跨越式发展的期望。
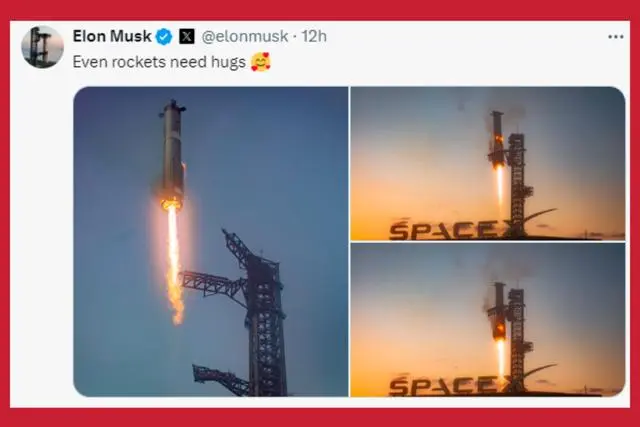
10月7日-13日被称为“马斯克周”,为什么呢?
(1)10月11日,马斯克发布了无人驾驶出租车CyberCab(无监督FSD),颠覆了人类对车的概念的理解。
(2)10月11日,马斯克发布能跟人互动的Optimus机器人。
(3)10月13日,马斯克麾下的太空探索技术公司(SpaceX)新一代重型运载火箭“星舰”第五次试飞成功,并在这一过程中实现了技术上的重大突破——首次尝试用发射塔的机械臂(形象地被称为“筷子”)在半空中捕获助推器以实现回收并取得成功。从成本、效率等各方面都可以看到,马斯克对AI的应用是超前的。
*新药研发AI设计周期可从5-6年提至1-2年
正是因为有这些工作展现,在社会各行业,无论是商业、金融、制造业、社会治理,还是医疗、教育、科研、服务等领域都在训练AI大模型,基于大模型展开应用。举例来说,在药物研究领域,原来发布一款新药一般需要5至10年,现在新药周期大规模缩减,方法就是基于数据预测。
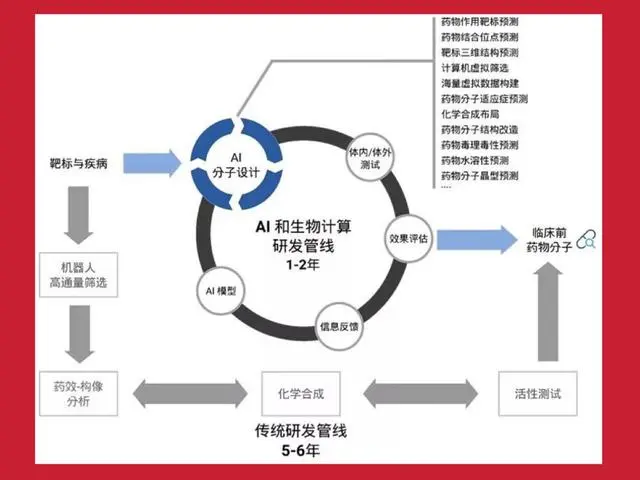
新药研发由于AI介入大大缩短时间
第二步要进入临床测试。所有的新药必须经过临床一期、二期确定安全后才能投放使用。人工智能在临床测试过程中也有许多帮助,主要是通过人工智能进行大量数据的对比和大批量数据处理。特别是前三年的疫情期间,美国与中国都在快速研究一些应对新冠的特效药,出药的时间比过去快多了。可以说,人工智能发展之后,极大提升了生物医药研发速度。
*大模型对算力需求为何增长很快?
人工智能的三要素包括算力、数据、算法。其中算法相对固定,数据也比较清晰,有大规模的数据才能训练数据,然后产生智能。
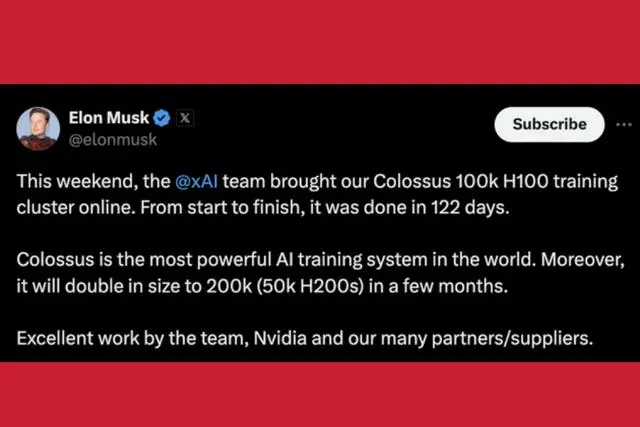
马斯克推特发布有关最快AI算力集群新闻
马斯克在今年上半年构建了一个基于GPU的最快算力系统,用10万张H100 GPU卡构成的AI集群系统来支撑他的自动驾驶和机器人。构建这样规模的机器,造价约40亿美元,每年功耗150兆瓦,电费高达1.2亿美元。如果国内要构建一个10万张规模能力的卡,假设美元与人民币等值,基本上也要花人民币40亿元,每年耗电约1.2亿元。
*10万卡集群规模建设即超算建设决定着各国算力实力
从超级计算机的角度来看,GPT就是一个典型的分布式和并行计算的应用。因为H系列、A系列的GPU卡是一个全能卡,超算、智算都可以做。受到美国的限制,国内许多常见的算力卡受到很大的限制,只能有16位或32位,这种情况下的GPU就只能做人工智能的大数据处理。所谓“智能算力”是国内的一种说法,国际上通常的说法是“AI超级计算机”,因为它本来做的就是一个超级计算机的应用。从整个机器来看,AI超级计算机原本就由10万张卡堆在一起,那么怎么把它们堆到一起?真正核心的其实是互联技术,能把上万张卡放到一起,做同一个题目,能够稳定计算至少几个小时。
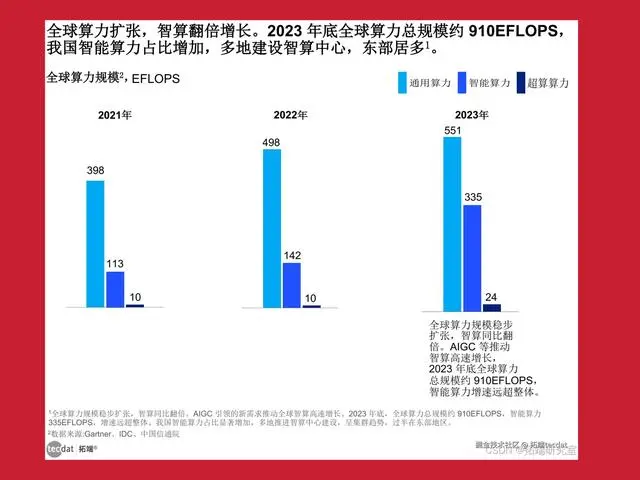
智算规模在2023年增速达136%
从国际上看,美国和中国在人工智能领域有大规模发力的建设。一方面,美国是由政府引导,头部公司发力。例如,Meta、微软&OpenAI、马斯克的xAI等多家AI巨头公司陆续宣布或者完成10万卡集群规模建设。据IDC统计,预计2022年至2032年全球人工智能产业规模的复合增长率高达42%,2032年将达到1.3万亿美元。至2023年底,全球算力总规模约为910EFlops,增长40%,智能算力规模达到335EFlops,增长达136%。
算力的发展与国家的实力密切相关,与GDP走势呈正相关。例如,算力发展较为迅速的美国和中国,GDP的体量也处于领先地位,属于第一梯队。日本、德国、法国、意大利等GDP在世界上占比较高的发达国家,属于第二梯队。其他发展中国家,以及规模较小的国家则属于第三梯队。
*中国算力建设加速,从“东数西算”到全国一体化算力网
算力代表新质生产力。2022年12月,国务院印发的《“十四五”数字经济发展规划》提出,到2025年,数字经济核心产业增加值占GDP比重达到10%的重要发展目标。2023年,中共中央、国务院印发了《数字中国建设整体布局规划》,其中明确提出,数字中国建设按照“2522”的整体框架进行布局。

国家发展改革委等多部门发布构建全国一体化算力网的实施意见
“东数西算”工程部署了8个枢纽节点,京津冀、长三角、粤港澳和成渝地区等4个信息化发达地区,主要负责应用算力。内蒙古、甘肃、宁夏、贵州等4个欠发达地区作为供给方,提供绿电并转化成算力。自2023年起至2024年6月底,八大国家枢纽节点直接投资超过435亿元,拉动投资超过2000亿元。各级地方政府把数字产业作为支柱产业发展,投入巨大。当然也给许多地区的经济带来了特别的发展。
国内三大电信运营商、互联网公司三巨头BAT(百度、阿里巴巴、腾讯),以及其他算力公司,都建设了万卡以上规模的算力来支撑我国的人工智能发展。
AI算力面临的挑战
大模型等人工智能的快速发展对算力有着强大的需求,资本和社会力量投入也日益增长,那么,大众期盼的算力为何不能如愿匹配呢?
*效率低下:集成电路自身限制和生态体系不完整

专家会员沈巍(中)主持,商汤科技大装置事业群生态执行总监刘远辉(右)和上海超算中心高性能计算部部长王涛参与
主讲之后,上海市算力网络协会专家们展开讨论
*能耗浪费:散热成本、数据搬运功耗、数据中心折旧
一方面,集成电路本身的特性使得其自身发热,这就是电力浪费,还要给其配置制冷设备,把它的热量带出去,这就是二次浪费。计算机中数据的传输成本非常高,例如,想从北京拷个数据到上海,可以通过网络传输,但是一旦达到P级(1PB=1024TB)或者再大规模的数据,网络传输的成本和速度就远远不如直接派人去北京把数据拷到硬盘里带回上海的速度和成本。事实上,微观的数据传输成本,即从一个CPU传到另一个CPU的成本也是最高的。有一个预测,当半导体工艺达到7纳米时,数据搬运功耗占总功耗的63.7%。也就是说,计算机里真正耗能的主要是数据的传递,在超级计算机里数据的同步和传输也是最花时间和电力的。
算法设计也是最重要的工作。例如并行计算。其实人类所有的工作都适合串行计算。到目前为止,计算机也无法自动实现并行计算,还需要人工介入把任务分配好。所以,真正的计算难度在于把计算机里这些成千上万个核同步调动起来,让它们干一件事情,这也需要耗能。

对计算机的散热,液冷是目前的解决方案
对于计算机的能耗,我们现在还只能做一些外围工作。对于如何降低计算机本身的电耗,目前还无解,就看下一代计算机是否有革命性的突破。目前算力中心采取了最先进的液冷,将整个计算机放到一种特殊的液体中进行制冷,但建设成本很高,初期的一次性投入非常大。如果把制冷液也计入成本,那从投资的角度来说,根本就没有节省。另一种方法是用所谓的绿电,如太阳能、水利发电,这种方法的污染相对较少。此外,最近也有观点提出把机器建到月球上。小规模的机器可以操作,但大规模的机器难以实现,因为机器本身十几兆、百兆瓦的耗电量,在月球上难以解决。所以,能耗问题是计算机非常头疼的一个问题。
*多样性需求提升和计算架构单一矛盾
人类需要计算机解决各种各样的问题,不论是场景环境还是种类需求都日益增多,但是计算机结构单一,解决方案就是一个单一结构或固定结构,计算机很难有一个动态的变化来适应人类的问题。对此,计算机科学家也在努力探索。
新一代AI算力展望
虽然挑战很大,但诸多方面都在展开攻关。我们可以展望下一代算力的前景。

5月15日,谷歌发布了第六代TPU芯片Trillium
从计算机硬件来看,在提高算法在机器里的效率上已发布一些新架构,如华为发布的人工智能专用处理单元NPU(Neural-network Processing Unit),即嵌入式神经网络处理器,就是针对人工智能升级网络设计的性能更优的芯片。谷歌向量计算也在做自己的TPU(Tensor Processing Unit,张量处理单元)芯片,还有使用场景更加灵活的FPGA(Field-Programmable Gate Array,现场可编程门阵列)芯片,以及针对特定应用领域的ASIC(Application-Specific Integrated Circuit,应用型专用集成电路)芯片。这些芯片结构可以提高我们解决问题的效率,但是通用性会差一些。幸好针对人工智能的算法是一个特定的算法,可以提高效率。
*软件创新:算法改变较难,软硬件结合为佳
从软件的角度出发,现在的计算方法与硬件的匹配关系较差,所以现在也在改变算法,但是算法也不容易改变。辛顿从1980年代就开始研究人工智能的卷积神经网络算法,尽管人工智能有许多算法的设计,但本质上不可能在短期内有更大突破,所以要将软硬件两者结合起来,尽可能提高效率。
*新型颠覆式计算机:存算一体、量子计算、生物存储、脑机接口
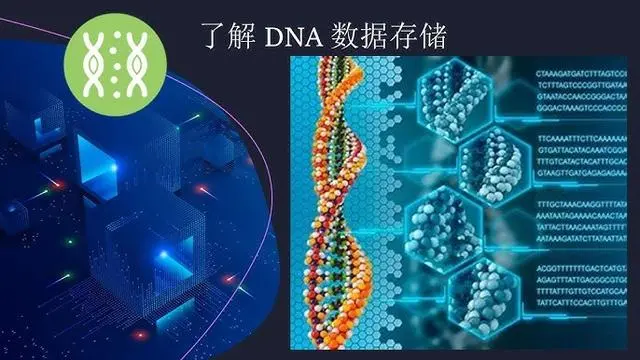
一是模拟人脑进行数据传输和运算的存算一体机。人脑本身就存储了许多信息,运算时只需要把两个神经元连接到一起。存算一体是打破冯·诺依曼结构的一个全新发展方向,目前也有一些成果。
二是量子计算。从计算机的角度看,我们期望量子计算的诞生,为计算机带来革命性的巨大发展。量子计算也有许多方法,如超导计算,在环境温度冷却到负273度的情况下产生超导,然后建立计算机基础。还有光子、中微子陷阱等方式。该领域目前国内也在积极研究,希望能够创造出颠覆性的成果。
三是生物存储。现在的存储还是集成电路,未来希望计算机能够模拟人类进行蛋白质结构存储。这方面目前也在进行一些实验,但距离投入使用还很遥远。

上图中心听众济济一堂,对新话题充满探索热情,近10万人次观看直播 孙科拍摄
作者:李根国(上海超算中心主任)
(如有版权问题,请联系删除)
