“为解决AI算力供给不足,除了选择英伟达,我们也可以用CPU芯片实现AI推理。”国内某云计算大厂基础设施负责人在年初一次技术分享会上表达。
该负责人所指的AI推理芯片市场需求量正逐年增长。VerifiedMarketResearch报告显示,2023年人工智能推理芯片市场规模为158亿美元,预计到2030年将达到906亿美元,在2024-2030年预测期内的复合年增长率为22.6%。
今年早些时候,英伟达财报会上也有表示,公司全年数据中心里已经有40%的收入来自推理业务。
分析其中缘由,除了边缘计算和物联网设备驱动外,更重要的是AI应用急剧扩张,相较于需要大规模算力的AI(大模型)训练场景,AI推理对算力性能要求没有AI训练严苛,主要是满足低功耗和实时处理的需求。但在部署在实际终端场景中时,会需要大量服务器进行并行网络计算,推理成本会骤然提升。
为此,硬件层面,厂商会不断升级处理器和加速器,从CPU到GPU、FPGA、TPU等,以提高在AI推理方面的性能和能效比。在软件和算法层面,厂商为大规模算力集群提供AI训练推理框架、软件框架,做软硬适配,同时在算法层面,如量化、稀疏化、蒸馏、剪枝等手段,从减少模型的计算复杂度和内存占用入手,以降低推理所需存算空间。
与此同时,据路透社报道,OpenAI 正在与博通(Broadcom)合作开发其首款定制 AI 推理芯片,旨在处理其大规模的AI工作负载,特别是推理任务。
这意味着,对企业客户而言,在模型推理或部署阶段,需要考虑部署灵活性、性价比以及低门槛接入方式,这些都决定了企业TCO(总体拥有成本,Total Cost of Ownership)。Melius Research的分析师Ben Reitzes在给客户的一份说明中表示:“有看法认为,英伟达未来在推理领域的市场份额将低于训练领域。”
有需求的地方就有市场,有市场的地方就有竞争。如今,AI推理市场正在被英特尔、AMD、高通等CPU厂商盯上。
以英特尔为例。10月28日,英特尔宣布扩容英特尔成都封装测试基地,其成都基地扩容主要有两方面:一是新增产能将集中在为服务器芯片提供封装测试服务,以响应中国客户市场需求;二是即将设立英特尔客户解决方案中心,推动为行业客户提供基于英特尔架构和产品的定制化方案。更早一个月,除了很早就预热的Gaudi 3 AI加速器,英特尔还升级至强6处理器,其性能是前代产品的两倍,可支持边缘、数据中心、云环境中的AI大模型推理诉求。据外媒报道,目前73%的AI服务器都使用英特尔至强系列作为服务器机头。
钛媒体注意到,仅在企业级应用市场,中国云厂商、OEM、ODM、ISV等伙伴正密集对其搭载CPU芯片的通用算力服务器进行升级。例如,阿里云基于方升架构推出最新一代磐久计算型服务器,以及第九代阿里云英特尔平台企业级计算实例产品;火山引擎对其第四代云服务器实例进行了架构和性能优化;在基于松耦合开放架构设计的服务器计算模组设计规范(OCM)下,浪潮信息元脑服务器第八代算力平台也于近日正式推出,同时支持英特尔至强6处理器及AMD EPYC 9005系列处理器。
那么从英特尔等的技术升级进程上可以理解,相比于昂贵且紧缺的GPU或者适合于小规模的RTX 4090,CPU处理器的能核能效正逐渐去适应AI工作负载和高密度可扩展的融合需求。
赵帅表示:“在AI训练场景中,CPU目前主要参与数据预处理环节,包括数据清洗、格式转换、特征提取等,目前大模型训练所需的数据集仍在呈指数级增长,需要有更强大的CPU。在AI推理场景,目前主流大模型月活非常高,这意味着AI推理需要同时处理高并发任务,对整个CPU的资源调度能力是一个极其严峻的考验。CPU需要在极短的时间内对各种任务进行合理分配和调度,确保每个任务都能得到及时处理和实时响应。”
在赵帅看来,多模态模型的出现,对内存容量提出了更大要求,以便支持数据预处理和存储。例如多模态模型LLaMA3.2包含60亿图文和1500小时的语音数据,数据规模达到PB级,相比LLaMA3.1的数据量已增加百倍以上。长本文的出现,导致某些先进创企已经提出要以KVCache为中心的分离架构设计,即根据不同计算特性将预填充服务器与解码服务器分开,在大batch size及队列场景下需要更大的系统内存带宽。此外,适配各种加速卡的处理器节点也面临算力、内存容量、内存带宽、IO扩展等多方面的挑战,需要丰富的强大的CPU系统生态来实现系统资源的最佳利用。
据工信部今年9月公布数据,中国在用算力中心机架总规模超过830万标准机架,算力总规模达246EFLOPS(EFLOPS是指每秒进行百亿亿次浮点运算)。据中国信通院测算,截至2023年底,全球算力基础设施总规模达到910EFLOPS,同比增长40%;其中,美国、中国算力基础设施规模位列前两名,算力占比分别为32%、26%。
那么问题来了,当算力中心仍在如火如荼建设中时,这种在数据、内存、算力、带宽等需求的急剧变化下,算力落地挑战将在未来被逐一放大。
不同于一年前市场端服务器采购的需求收紧,服务器尤其是AI服务器在大模型应用需求的拉动下,市场需求开始复苏。Gartner数据显示,2024 年第一季度,全球服务器出货量同比增长 5.9%,总出货量达 282 万台。本季度供应商收入同比增长 59.9%,AI服务器需求推动平均售价增长 51.0%。而在全球服务器市场强劲增长的态势中,浪潮信息服务器出货量全球第二,中国第一。
“我们面向于多场景需求满足,每款产品都基于具体业务场景和客户真实收益而来。你会发现我们的产品布局相较于其他厂商更为广泛。这一优势很大程度上归功于我们现行的解耦设计与开发模式。”赵帅对钛媒体表示。
他指出,从客户角度,往往面临各种特定的方案需求场景。通过将部件设计成通用的构建模块(CBB),这些模块经过一次测试和验证后,便能在多个平台上高效应用,从而支撑起浪潮信息广泛的产品布局,这也使得产品在更细分的场景中能够发挥更高价值。
浪潮信息服务器产品线规划经理罗剑告诉钛媒体,“第八代算力平台最核心的技术攻关,一是提升了软件方面的智能化水平,比如故障告警的智能化处理水平,通过大模型对过去历史故障数据进行建模,对关键部件如内存、硬盘等可能产生的故障进行智能预判,从而减少客户计划停机外的业务影响;二是计算模组的解耦,还有内存带宽的提升,破除存储墙、内存墙。尤其是支持更高计算性能的处理器,会有大量数据吞吐需求,针对大内存带宽需求,元脑服务器可配备最高12T内存,同时也可支持内存容量和带宽同步扩展的CXL方案,其目的也是释放计算性能的最大潜力,避免客户在内存资源上的闲置。”
钛媒体注意到,目前基于OCM、OAM、CXL、整机柜标准的开放产品,浪潮信息实现了在计算、存储、I/O扩展、整机柜部署和智算的五种场景化优化机型。除了在硬件层面,浪潮信息此前基于龙蜥社区开发的下游商业版服务器操作系统KOS进行了升级,实现软硬协同优化。
此外,过去一个月内,不只是浪潮信息,中兴通讯、联想、新华三等服务器厂商相继公布多款算力新品,同样覆盖了通用算力、人工智能、液冷、存储型等多个用途场景。一位服务器售前专家与钛媒体交流时指出,他们围绕下游客户诉求而采取的是earlyship策略,“在还没有交付时,实现大批量提前供应,其优势在于能保证建设时客户拿到的是真正先进的芯片。”
该负责人所指的AI推理芯片市场需求量正逐年增长。VerifiedMarketResearch报告显示,2023年人工智能推理芯片市场规模为158亿美元,预计到2030年将达到906亿美元,在2024-2030年预测期内的复合年增长率为22.6%。
今年早些时候,英伟达财报会上也有表示,公司全年数据中心里已经有40%的收入来自推理业务。
分析其中缘由,除了边缘计算和物联网设备驱动外,更重要的是AI应用急剧扩张,相较于需要大规模算力的AI(大模型)训练场景,AI推理对算力性能要求没有AI训练严苛,主要是满足低功耗和实时处理的需求。但在部署在实际终端场景中时,会需要大量服务器进行并行网络计算,推理成本会骤然提升。
为此,硬件层面,厂商会不断升级处理器和加速器,从CPU到GPU、FPGA、TPU等,以提高在AI推理方面的性能和能效比。在软件和算法层面,厂商为大规模算力集群提供AI训练推理框架、软件框架,做软硬适配,同时在算法层面,如量化、稀疏化、蒸馏、剪枝等手段,从减少模型的计算复杂度和内存占用入手,以降低推理所需存算空间。
“不可能三角”下的AI推理
与此同时,据路透社报道,OpenAI 正在与博通(Broadcom)合作开发其首款定制 AI 推理芯片,旨在处理其大规模的AI工作负载,特别是推理任务。
这意味着,对企业客户而言,在模型推理或部署阶段,需要考虑部署灵活性、性价比以及低门槛接入方式,这些都决定了企业TCO(总体拥有成本,Total Cost of Ownership)。Melius Research的分析师Ben Reitzes在给客户的一份说明中表示:“有看法认为,英伟达未来在推理领域的市场份额将低于训练领域。”
有需求的地方就有市场,有市场的地方就有竞争。如今,AI推理市场正在被英特尔、AMD、高通等CPU厂商盯上。
以英特尔为例。10月28日,英特尔宣布扩容英特尔成都封装测试基地,其成都基地扩容主要有两方面:一是新增产能将集中在为服务器芯片提供封装测试服务,以响应中国客户市场需求;二是即将设立英特尔客户解决方案中心,推动为行业客户提供基于英特尔架构和产品的定制化方案。更早一个月,除了很早就预热的Gaudi 3 AI加速器,英特尔还升级至强6处理器,其性能是前代产品的两倍,可支持边缘、数据中心、云环境中的AI大模型推理诉求。据外媒报道,目前73%的AI服务器都使用英特尔至强系列作为服务器机头。
钛媒体注意到,仅在企业级应用市场,中国云厂商、OEM、ODM、ISV等伙伴正密集对其搭载CPU芯片的通用算力服务器进行升级。例如,阿里云基于方升架构推出最新一代磐久计算型服务器,以及第九代阿里云英特尔平台企业级计算实例产品;火山引擎对其第四代云服务器实例进行了架构和性能优化;在基于松耦合开放架构设计的服务器计算模组设计规范(OCM)下,浪潮信息元脑服务器第八代算力平台也于近日正式推出,同时支持英特尔至强6处理器及AMD EPYC 9005系列处理器。
那么从英特尔等的技术升级进程上可以理解,相比于昂贵且紧缺的GPU或者适合于小规模的RTX 4090,CPU处理器的能核能效正逐渐去适应AI工作负载和高密度可扩展的融合需求。
CPU用于AI算力背后的几点变化
赵帅表示:“在AI训练场景中,CPU目前主要参与数据预处理环节,包括数据清洗、格式转换、特征提取等,目前大模型训练所需的数据集仍在呈指数级增长,需要有更强大的CPU。在AI推理场景,目前主流大模型月活非常高,这意味着AI推理需要同时处理高并发任务,对整个CPU的资源调度能力是一个极其严峻的考验。CPU需要在极短的时间内对各种任务进行合理分配和调度,确保每个任务都能得到及时处理和实时响应。”
在赵帅看来,多模态模型的出现,对内存容量提出了更大要求,以便支持数据预处理和存储。例如多模态模型LLaMA3.2包含60亿图文和1500小时的语音数据,数据规模达到PB级,相比LLaMA3.1的数据量已增加百倍以上。长本文的出现,导致某些先进创企已经提出要以KVCache为中心的分离架构设计,即根据不同计算特性将预填充服务器与解码服务器分开,在大batch size及队列场景下需要更大的系统内存带宽。此外,适配各种加速卡的处理器节点也面临算力、内存容量、内存带宽、IO扩展等多方面的挑战,需要丰富的强大的CPU系统生态来实现系统资源的最佳利用。
据工信部今年9月公布数据,中国在用算力中心机架总规模超过830万标准机架,算力总规模达246EFLOPS(EFLOPS是指每秒进行百亿亿次浮点运算)。据中国信通院测算,截至2023年底,全球算力基础设施总规模达到910EFLOPS,同比增长40%;其中,美国、中国算力基础设施规模位列前两名,算力占比分别为32%、26%。
那么问题来了,当算力中心仍在如火如荼建设中时,这种在数据、内存、算力、带宽等需求的急剧变化下,算力落地挑战将在未来被逐一放大。
更重要的是满足场景需要
不同于一年前市场端服务器采购的需求收紧,服务器尤其是AI服务器在大模型应用需求的拉动下,市场需求开始复苏。Gartner数据显示,2024 年第一季度,全球服务器出货量同比增长 5.9%,总出货量达 282 万台。本季度供应商收入同比增长 59.9%,AI服务器需求推动平均售价增长 51.0%。而在全球服务器市场强劲增长的态势中,浪潮信息服务器出货量全球第二,中国第一。
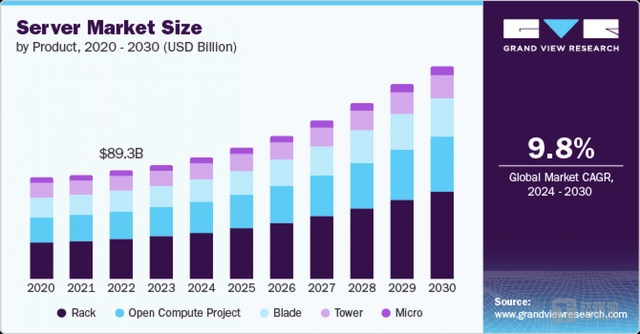
2020-2030全球服务器市场规模(按产品划分)
“我们面向于多场景需求满足,每款产品都基于具体业务场景和客户真实收益而来。你会发现我们的产品布局相较于其他厂商更为广泛。这一优势很大程度上归功于我们现行的解耦设计与开发模式。”赵帅对钛媒体表示。
他指出,从客户角度,往往面临各种特定的方案需求场景。通过将部件设计成通用的构建模块(CBB),这些模块经过一次测试和验证后,便能在多个平台上高效应用,从而支撑起浪潮信息广泛的产品布局,这也使得产品在更细分的场景中能够发挥更高价值。
浪潮信息服务器产品线规划经理罗剑告诉钛媒体,“第八代算力平台最核心的技术攻关,一是提升了软件方面的智能化水平,比如故障告警的智能化处理水平,通过大模型对过去历史故障数据进行建模,对关键部件如内存、硬盘等可能产生的故障进行智能预判,从而减少客户计划停机外的业务影响;二是计算模组的解耦,还有内存带宽的提升,破除存储墙、内存墙。尤其是支持更高计算性能的处理器,会有大量数据吞吐需求,针对大内存带宽需求,元脑服务器可配备最高12T内存,同时也可支持内存容量和带宽同步扩展的CXL方案,其目的也是释放计算性能的最大潜力,避免客户在内存资源上的闲置。”
钛媒体注意到,目前基于OCM、OAM、CXL、整机柜标准的开放产品,浪潮信息实现了在计算、存储、I/O扩展、整机柜部署和智算的五种场景化优化机型。除了在硬件层面,浪潮信息此前基于龙蜥社区开发的下游商业版服务器操作系统KOS进行了升级,实现软硬协同优化。
此外,过去一个月内,不只是浪潮信息,中兴通讯、联想、新华三等服务器厂商相继公布多款算力新品,同样覆盖了通用算力、人工智能、液冷、存储型等多个用途场景。一位服务器售前专家与钛媒体交流时指出,他们围绕下游客户诉求而采取的是earlyship策略,“在还没有交付时,实现大批量提前供应,其优势在于能保证建设时客户拿到的是真正先进的芯片。”
算力多元化时代,用户根据场景来选择不同的算力单元,满足不同的计算需求,服务器厂商为满足客户诉求也不再局限于提供单一算力产品。
(如有版权问题,请联系删除)
